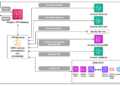
in my weblog publish, I had explored the best way to construct a Multi-agent SQL assistant utilizing CrewAI & Streamlit. The person may question a SQLite database in pure language. The AI brokers would generate a SQL question primarily based on person enter, overview it, and verify for compliance earlier than operating it towards the database to get outcomes. I additionally applied a human-in-the-loop checkpoint to take care of management and displayed the LLM prices related to each question for transparency and price management. Whereas the prototype was nice and generated good outcomes for my small demo database, I knew this is able to not be sufficient for real-life databases. Within the earlier setup, I used to be sending the entire database schema as context together with the person enter. As database schemas develop bigger, passing the complete schema to the LLM will increase token utilization, slows down response occasions, and makes hallucination extra seemingly. I wanted a strategy to feed solely related schema snippets to the LLM. That is the place RAG (Retrieval Augmented Era) is available in.
On this weblog publish, I construct a RAG supervisor and add a number of RAG methods to my SQL assistant to match their efficiency on metrics like response time and token utilization. The assistant now helps 4 RAG methods:
- No RAG: Passes the complete schema (baseline for comparability)
- Key phrase RAG: Makes use of domain-specific key phrase matching to pick out related tables
- FAISS RAG: Leverages semantic vector similarity by way of FAISS with
all-MiniLM-L6-v2embeddings - Chroma RAG: A persistent vector retailer resolution with ChromaDB for scalable production-grade search
For this challenge, I solely centered on RAG methods which are sensible, light-weight, and cost-efficient (free). You possibly can add any variety of implementations on prime and select one of the best one on your case. To facilitate experimentation and evaluation, I constructed an interactive efficiency comparability device that evaluates token discount, desk depend, response time, and question accuracy throughout all 4 methods.

Constructing a RAG Supervisor
The rag_manager.py file incorporates the complete implementation for the RAG supervisor. First, I created a BaseRAG class – a template that I take advantage of for all my completely different RAG methods. It makes certain each RAG strategy follows the identical construction. Any new technique could have two issues: a way to fetch the related schema primarily based on the person question, and one other technique that explains what the strategy is about. By utilizing the summary base class (ABC), I hold the code clear, modular, and straightforward to increase later.
from typing import Dict, Listing, Any, Non-compulsory
from abc import ABC, abstractmethod
class BaseRAG(ABC):
"""Base class for all RAG implementations."""
def __init__(self, db_path: str = DB_PATH):
self.db_path = db_path
self.identify = self.__class__.__name__
@abstractmethod
def get_relevant_schema(self, user_query: str, max_tables: int = 5) -> str:
"""Get related schema for the person question."""
go
@abstractmethod
def get_approach_info(self) -> Dict[str, Any]:
"""Get details about this RAG strategy."""
go
No RAG Technique
That is principally the identical strategy that I used beforehand, the place I despatched in the complete database schema as context to the LLM with none filtering or optimization. This strategy is greatest for very small schemas (ideally lower than 10 tables).
class NoRAG(BaseRAG):
"""No RAG - returns full schema."""
def get_relevant_schema(self, user_query: str, max_tables: int = 5) -> str:
return get_structured_schema(self.db_path)
def get_approach_info(self) -> Dict[str, Any]:
return {
"identify": "No RAG (Full Schema)",
"description": "Makes use of full database schema",
"professionals": ["Simple", "Always complete", "No setup required"],
"cons": ["High token usage", "Slower for large schemas"],
"best_for": "Small schemas (< 10 tables)"
}
Key phrase RAG Technique
Within the key phrase RAG strategy, I take advantage of a bunch of predefined key phrases mapped to every desk within the schema. When a person asks one thing, the system checks for key phrase matches within the question and picks out solely probably the most related tables. This fashion, I don’t ship the complete schema to the LLM – saving tokens and dashing issues up. It really works properly when your schema is acquainted and your queries are business-related or comply with widespread patterns.
The _build_table_keywords(self) technique is the core of how the key phrase matching logic works. It incorporates a hardcoded key phrase mapping for every desk within the schema. It helps to affiliate person question phrases (like “gross sales”, “model”, “buyer”) with the more than likely related tables.
class KeywordRAG(BaseRAG):
"""Key phrase-based RAG utilizing enterprise context matching."""
def __init__(self, db_path: str = DB_PATH):
tremendous().__init__(db_path)
self.table_keywords = self._build_table_keywords()
def _build_table_keywords(self) -> Dict[str, List[str]]:
"""Construct key phrase mappings for every desk."""
return {
'merchandise': ['product', 'item', 'catalog', 'price', 'category', 'brand', 'sales', 'sold'],
'product_variants': ['variant', 'product', 'sku', 'color', 'size', 'brand', 'sales', 'sold'],
'clients': ['customer', 'user', 'client', 'buyer', 'person', 'email', 'name'],
'orders': ['order', 'purchase', 'transaction', 'sale', 'buy', 'total', 'amount', 'sales'],
'order_items': ['item', 'product', 'quantity', 'line', 'detail', 'sales', 'sold', 'brand'],
'funds': ['payment', 'pay', 'money', 'revenue', 'amount'],
'stock': ['inventory', 'stock', 'quantity', 'warehouse', 'available'],
'evaluations': ['review', 'rating', 'feedback', 'comment', 'opinion'],
'suppliers': ['supplier', 'vendor', 'procurement', 'purchase'],
'classes': ['category', 'type', 'classification', 'group'],
'manufacturers': ['brand', 'manufacturer', 'company', 'sales', 'sold', 'quantity', 'total'],
'addresses': ['address', 'location', 'shipping', 'billing'],
'shipments': ['shipment', 'delivery', 'shipping', 'tracking'],
'reductions': ['discount', 'coupon', 'promotion', 'offer'],
'warehouses': ['warehouse', 'facility', 'location', 'storage'],
'workers': ['employee', 'staff', 'worker', 'person'],
'departments': ['department', 'division', 'team'],
'product_images': ['image', 'photo', 'picture', 'media'],
'purchase_orders': ['purchase', 'procurement', 'supplier', 'order'],
'purchase_order_items': ['purchase', 'procurement', 'supplier', 'item'],
'order_discounts': ['discount', 'coupon', 'promotion', 'order'],
'shipment_items': ['shipment', 'delivery', 'item', 'tracking']
}
def get_relevant_schema(self, user_query: str, max_tables: int = 5) -> str:
import re
# Rating tables by key phrase relevance
query_words = set(re.findall(r'bw+b', user_query.decrease()))
table_scores = {}
for table_name, key phrases in self.table_keywords.objects():
rating = 0
# Depend key phrase matches
for key phrase in key phrases:
if key phrase in query_words:
rating += 3
# Partial matches
for query_word in query_words:
if key phrase in query_word or query_word in key phrase:
rating += 1
# Bonus for actual desk identify match
if table_name.decrease() in query_words:
rating += 10
table_scores[table_name] = rating
# Get prime scoring tables
sorted_tables = sorted(table_scores.objects(), key=lambda x: x[1], reverse=True)
relevant_tables = [table for table, score in sorted_tables[:max_tables] if rating > 0]
# Fallback to default tables if no matches
if not relevant_tables:
relevant_tables = self._get_default_tables(user_query)[:max_tables]
# Construct schema for chosen tables
return self._build_schema(relevant_tables)
def _get_default_tables(self, user_query: str) -> Listing[str]:
"""Get default tables primarily based on question patterns."""
query_lower = user_query.decrease()
# Gross sales/income queries
if any(phrase in query_lower for phrase in ['revenue', 'sales', 'total', 'amount', 'brand']):
return ['orders', 'order_items', 'product_variants', 'products', 'brands']
# Product queries
if any(phrase in query_lower for phrase in ['product', 'item', 'catalog']):
return ['products', 'product_variants', 'categories', 'brands']
# Buyer queries
if any(phrase in query_lower for phrase in ['customer', 'user', 'buyer']):
return ['customers', 'orders', 'addresses']
# Default
return ['products', 'customers', 'orders', 'order_items']
def _build_schema(self, table_names: Listing[str]) -> str:
"""Construct schema string for specified tables."""
if not table_names:
return get_structured_schema(self.db_path)
conn = sqlite3.join(self.db_path)
cursor = conn.cursor()
schema_lines = ["Available tables and columns:"]
strive:
for table_name in table_names:
cursor.execute(f"PRAGMA table_info({table_name});")
columns = cursor.fetchall()
if columns:
col_names = [col[1] for col in columns]
schema_lines.append(f"- {table_name}: {', '.be a part of(col_names)}")
lastly:
conn.shut()
return 'n'.be a part of(schema_lines)
def get_approach_info(self) -> Dict[str, Any]:
return {
"identify": "Key phrase RAG",
"description": "Makes use of enterprise context key phrases to match related tables",
"professionals": ["Fast", "No external dependencies", "Good for business queries"],
"cons": ["Limited by predefined keywords", "May miss complex relationships"],
"best_for": "Enterprise queries with clear area phrases"
}
FAISS RAG Method
The FAISS RAG technique is the place issues begin getting smarter. As a substitute of dumping the entire schema, I embed every desk’s metadata (columns, relationships, enterprise context) into vectors utilizing a sentence transformer. When the person asks a query, it’s embedded into that question too and makes use of FAISS to do a semantic search matching on the “which means” as an alternative of simply key phrases. It’s good for queries the place customers aren’t being very particular or when tables have associated phrases. I like FAISS as a result of it’s free, runs regionally, and provides fairly correct outcomes whereas saving tokens.
The one catch is that setting it up takes some additional steps, and it makes use of extra reminiscence than fundamental approaches. LLMs and embedding fashions don’t know what your tables imply except you clarify it to them. Within the _get_business_context() technique, we have to manually write a brief description of what every desk represents within the enterprise.
Within the _extract_table_info() technique, I pull in desk names, column names, and international key relationships from SQLite’s PRAGMA queries to construct a dictionary with structured data about every desk. Lastly, within the _create_table_description() technique, complete descriptions for every desk are constructed to be embedded by a SentenceTransformer.
class FAISSVectorRAG(BaseRAG):
"""FAISS-based vector RAG utilizing sentence transformers."""
def __init__(self, db_path: str = DB_PATH):
tremendous().__init__(db_path)
self.mannequin = None
self.index = None
self.table_info = {}
self.table_names = []
self._initialize()
def _initialize(self):
"""Initialize the FAISS vector retailer and embeddings."""
strive:
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
print("🔄 Initializing FAISS Vector RAG...")
# Load embedding mannequin
self.mannequin = SentenceTransformer('all-MiniLM-L6-v2')
print("✅ Loaded embedding mannequin: all-MiniLM-L6-v2")
# Extract desk data and create embeddings
self.table_info = self._extract_table_info()
# Create embeddings for every desk
table_descriptions = []
self.table_names = []
for table_name, data in self.table_info.objects():
description = self._create_table_description(table_name, data)
table_descriptions.append(description)
self.table_names.append(table_name)
# Generate embeddings
print(f"🔄 Producing embeddings for {len(table_descriptions)} tables...")
embeddings = self.mannequin.encode(table_descriptions)
# Create FAISS index
dimension = embeddings.form[1]
self.index = faiss.IndexFlatIP(dimension) # Interior product for cosine similarity
# Normalize embeddings for cosine similarity
faiss.normalize_L2(embeddings)
self.index.add(embeddings.astype('float32'))
print(f"✅ FAISS Vector RAG initialized with {len(table_descriptions)} tables")
besides Exception as e:
print(f"❌ Error initializing FAISS Vector RAG: {e}")
self.mannequin = None
self.index = None
def _extract_table_info(self) -> Dict[str, Dict]:
"""Extract detailed details about every desk."""
conn = sqlite3.join(self.db_path)
cursor = conn.cursor()
table_info = {}
strive:
# Get all desk names
cursor.execute("SELECT identify FROM sqlite_master WHERE sort='desk';")
tables = cursor.fetchall()
for (table_name,) in tables:
data = {
'columns': [],
'foreign_keys': [],
'business_context': self._get_business_context(table_name)
}
# Get column data
cursor.execute(f"PRAGMA table_info({table_name});")
columns = cursor.fetchall()
for col in columns:
data['columns'].append({
'identify': col[1],
'sort': col[2],
'primary_key': bool(col[5])
})
# Get international key data
cursor.execute(f"PRAGMA foreign_key_list({table_name});")
fks = cursor.fetchall()
for fk in fks:
data['foreign_keys'].append({
'column': fk[3],
'references_table': fk[2],
'references_column': fk[4]
})
table_info[table_name] = data
lastly:
conn.shut()
return table_info
def _get_business_context(self, table_name: str) -> str:
"""Get enterprise context description for tables."""
contexts = {
'merchandise': 'Product catalog with objects, costs, classes, and model data. Core stock knowledge.',
'product_variants': 'Product variations like colours, sizes, SKUs. Hyperlinks merchandise to particular sellable objects.',
'clients': 'Buyer profiles with private data, contact particulars, and account standing.',
'orders': 'Buy transactions with totals, dates, standing, and buyer relationships.',
'order_items': 'Particular person line objects inside orders. Comprises portions, costs, and product references.',
'funds': 'Fee processing data with strategies, quantities, and transaction standing.',
'stock': 'Inventory ranges and warehouse portions for product variants.',
'evaluations': 'Buyer suggestions, scores, and product evaluations.',
'suppliers': 'Vendor data for procurement and provide chain administration.',
'classes': 'Product categorization hierarchy for organizing catalog.',
'manufacturers': 'Model data for merchandise and advertising functions.',
'addresses': 'Buyer delivery and billing tackle data.',
'shipments': 'Supply monitoring and delivery standing data.',
'reductions': 'Promotional codes, coupons, and low cost campaigns.',
'warehouses': 'Storage facility places and warehouse administration.',
'workers': 'Employees data and organizational construction.',
'departments': 'Organizational divisions and crew construction.',
'product_images': 'Product pictures and media property.',
'purchase_orders': 'Procurement orders from suppliers.',
'purchase_order_items': 'Line objects for provider buy orders.',
'order_discounts': 'Utilized reductions and promotions on orders.',
'shipment_items': 'Particular person objects inside cargo packages.'
}
return contexts.get(table_name, f'Database desk for {table_name} associated operations.')
def _create_table_description(self, table_name: str, data: Dict) -> str:
"""Create a complete description for embedding."""
description = f"Desk: {table_name}n"
description += f"Objective: {data['business_context']}n"
# Add column data
description += "Columns: "
col_names = [col['name'] for col in data['columns']]
description += ", ".be a part of(col_names) + "n"
# Add relationship data
if data['foreign_keys']:
description += "Relationships: "
relationships = []
for fk in data['foreign_keys']:
relationships.append(f"hyperlinks to {fk['references_table']} by way of {fk['column']}")
description += "; ".be a part of(relationships) + "n"
# Add widespread use instances primarily based on desk sort
use_cases = self._get_use_cases(table_name)
if use_cases:
description += f"Widespread queries: {use_cases}"
return description
def _get_use_cases(self, table_name: str) -> str:
"""Get widespread use instances for every desk."""
use_cases = {
'merchandise': 'product searches, catalog listings, value queries, stock checks',
'clients': 'buyer lookup, registration evaluation, geographic distribution',
'orders': 'gross sales evaluation, income monitoring, order historical past, standing monitoring',
'order_items': 'product gross sales efficiency, income by product, order composition',
'funds': 'cost processing, income reconciliation, cost technique evaluation',
'manufacturers': 'model efficiency, gross sales by model, model comparability',
'classes': 'class evaluation, product group, catalog construction'
}
return use_cases.get(table_name, 'common knowledge queries and evaluation')
def get_relevant_schema(self, user_query: str, max_tables: int = 5) -> str:
"""Get related schema utilizing vector similarity search."""
if self.mannequin is None or self.index is None:
print("⚠️ FAISS not initialized, falling again to full schema")
return get_structured_schema(self.db_path)
strive:
import faiss
import numpy as np
# Generate question embedding
query_embedding = self.mannequin.encode([user_query])
faiss.normalize_L2(query_embedding)
# Seek for related tables
scores, indices = self.index.search(query_embedding.astype('float32'), max_tables)
# Get related desk names
relevant_tables = []
for i, (rating, idx) in enumerate(zip(scores[0], indices[0])):
if idx < len(self.table_names) and rating > 0.1: # Minimal similarity threshold
relevant_tables.append(self.table_names[idx])
# Fallback if no related tables discovered
if not relevant_tables:
print("⚠️ No related tables discovered, utilizing defaults")
relevant_tables = self._get_default_tables(user_query)[:max_tables]
# Construct schema for chosen tables
return self._build_schema(relevant_tables)
besides Exception as e:
print(f"⚠️ Vector search failed: {e}, falling again to full schema")
return get_structured_schema(self.db_path)
def _get_default_tables(self, user_query: str) -> Listing[str]:
"""Get default tables primarily based on question patterns."""
query_lower = user_query.decrease()
if any(phrase in query_lower for phrase in ['revenue', 'sales', 'total', 'amount', 'brand']):
return ['orders', 'order_items', 'product_variants', 'products', 'brands']
elif any(phrase in query_lower for phrase in ['product', 'item', 'catalog']):
return ['products', 'product_variants', 'categories', 'brands']
elif any(phrase in query_lower for phrase in ['customer', 'user', 'buyer']):
return ['customers', 'orders', 'addresses']
else:
return ['products', 'customers', 'orders', 'order_items']
def _build_schema(self, table_names: Listing[str]) -> str:
"""Construct schema string for specified tables."""
if not table_names:
return get_structured_schema(self.db_path)
conn = sqlite3.join(self.db_path)
cursor = conn.cursor()
schema_lines = ["Available tables and columns:"]
strive:
for table_name in table_names:
cursor.execute(f"PRAGMA table_info({table_name});")
columns = cursor.fetchall()
if columns:
col_names = [col[1] for col in columns]
schema_lines.append(f"- {table_name}: {', '.be a part of(col_names)}")
lastly:
conn.shut()
return 'n'.be a part of(schema_lines)
def get_approach_info(self) -> Dict[str, Any]:
return {
"identify": "FAISS Vector RAG",
"description": "Makes use of semantic embeddings and vector similarity search",
"professionals": ["Semantic understanding", "Handles complex queries", "No API costs"],
"cons": ["Requires model download", "Higher memory usage", "Setup complexity"],
"best_for": "Complicated queries, giant schemas, semantic relationships"
}
Chroma RAG Technique
Chroma RAG is a extra production-friendly model of FAISS as a result of it presents persistent storage. As a substitute of conserving embeddings in reminiscence, Chroma shops them regionally, so even when I restart the app, the vector index remains to be there. Similar to in FAISS, I nonetheless have to manually describe what every desk does in enterprise phrases (in _get_business_context()). I embed my schema descriptions and retailer them in ChromaDB. Upon initialization, sentence-transformer (MiniLM) is loaded. If the vector already exists, it’s loaded. If not, I extract data + descriptions and name _populate_collection() to generate and retailer vectors. This course of solely must be executed as soon as or when the schema adjustments.
It’s quick, constant throughout classes, and straightforward to arrange. I selected it as a result of it’s free, doesn’t want exterior companies, and works properly for real-world use instances the place you wish to scale with out worrying about dropping the vector index or reprocessing every little thing each time.
class ChromaVectorRAG(BaseRAG):
"""Chroma-based vector RAG utilizing sentence transformers with persistent storage."""
def __init__(self, db_path: str = DB_PATH):
tremendous().__init__(db_path)
self.mannequin = None
self.chroma_client = None
self.assortment = None
self.table_info = {}
self.table_names = []
self._initialize()
def _initialize(self):
"""Initialize the Chroma vector retailer and embeddings."""
strive:
import chromadb
from sentence_transformers import SentenceTransformer
print("🔄 Initializing Chroma Vector RAG...")
# Load embedding mannequin
self.mannequin = SentenceTransformer('all-MiniLM-L6-v2')
print("✅ Loaded embedding mannequin: all-MiniLM-L6-v2")
# Initialize Chroma shopper (persistent storage)
self.chroma_client = chromadb.PersistentClient(path="./knowledge/chroma_db")
# Get or create assortment
collection_name = "schema_tables"
strive:
self.assortment = self.chroma_client.get_collection(collection_name)
print("✅ Loaded current Chroma assortment")
besides:
# Create new assortment if it would not exist
self.assortment = self.chroma_client.create_collection(
identify=collection_name,
metadata={"description": "Database schema desk embeddings"}
)
print("✅ Created new Chroma assortment")
# Extract desk data and create embeddings
self.table_info = self._extract_table_info()
self._populate_collection()
# Load desk names for reference
self._load_table_names()
print(f"✅ Chroma Vector RAG initialized with {len(self.table_names)} tables")
besides Exception as e:
print(f"❌ Error initializing Chroma Vector RAG: {e}")
self.mannequin = None
self.chroma_client = None
self.assortment = None
def _extract_table_info(self) -> Dict[str, Dict]:
"""Extract detailed details about every desk."""
conn = sqlite3.join(self.db_path)
cursor = conn.cursor()
table_info = {}
strive:
# Get all desk names
cursor.execute("SELECT identify FROM sqlite_master WHERE sort='desk';")
tables = cursor.fetchall()
for (table_name,) in tables:
data = {
'columns': [],
'foreign_keys': [],
'business_context': self._get_business_context(table_name)
}
# Get column data
cursor.execute(f"PRAGMA table_info({table_name});")
columns = cursor.fetchall()
for col in columns:
data['columns'].append({
'identify': col[1],
'sort': col[2],
'primary_key': bool(col[5])
})
# Get international key data
cursor.execute(f"PRAGMA foreign_key_list({table_name});")
fks = cursor.fetchall()
for fk in fks:
data['foreign_keys'].append({
'column': fk[3],
'references_table': fk[2],
'references_column': fk[4]
})
table_info[table_name] = data
lastly:
conn.shut()
return table_info
def _get_business_context(self, table_name: str) -> str:
"""Get enterprise context description for tables."""
contexts = {
'merchandise': 'Product catalog with objects, costs, classes, and model data. Core stock knowledge.',
'product_variants': 'Product variations like colours, sizes, SKUs. Hyperlinks merchandise to particular sellable objects.',
'clients': 'Buyer profiles with private data, contact particulars, and account standing.',
'orders': 'Buy transactions with totals, dates, standing, and buyer relationships.',
'order_items': 'Particular person line objects inside orders. Comprises portions, costs, and product references.',
'funds': 'Fee processing data with strategies, quantities, and transaction standing.',
'stock': 'Inventory ranges and warehouse portions for product variants.',
'evaluations': 'Buyer suggestions, scores, and product evaluations.',
'suppliers': 'Vendor data for procurement and provide chain administration.',
'classes': 'Product categorization hierarchy for organizing catalog.',
'manufacturers': 'Model data for merchandise and advertising functions.',
'addresses': 'Buyer delivery and billing tackle data.',
'shipments': 'Supply monitoring and delivery standing data.',
'reductions': 'Promotional codes, coupons, and low cost campaigns.',
'warehouses': 'Storage facility places and warehouse administration.',
'workers': 'Employees data and organizational construction.',
'departments': 'Organizational divisions and crew construction.',
'product_images': 'Product pictures and media property.',
'purchase_orders': 'Procurement orders from suppliers.',
'purchase_order_items': 'Line objects for provider buy orders.',
'order_discounts': 'Utilized reductions and promotions on orders.',
'shipment_items': 'Particular person objects inside cargo packages.'
}
return contexts.get(table_name, f'Database desk for {table_name} associated operations.')
def _populate_collection(self):
"""Populate Chroma assortment with desk embeddings."""
if not self.assortment or not self.table_info:
return
paperwork = []
metadatas = []
ids = []
for table_name, data in self.table_info.objects():
# Create complete description
description = self._create_table_description(table_name, data)
paperwork.append(description)
metadatas.append({
'table_name': table_name,
'column_count': len(data['columns']),
'has_foreign_keys': len(data['foreign_keys']) > 0,
'business_context': data['business_context']
})
ids.append(f"table_{table_name}")
# Add to assortment
self.assortment.add(
paperwork=paperwork,
metadatas=metadatas,
ids=ids
)
print(f"✅ Added {len(paperwork)} desk embeddings to Chroma assortment")
def _create_table_description(self, table_name: str, data: Dict) -> str:
"""Create a complete description for embedding."""
description = f"Desk: {table_name}n"
description += f"Objective: {data['business_context']}n"
# Add column data
description += "Columns: "
col_names = [col['name'] for col in data['columns']]
description += ", ".be a part of(col_names) + "n"
# Add relationship data
if data['foreign_keys']:
description += "Relationships: "
relationships = []
for fk in data['foreign_keys']:
relationships.append(f"hyperlinks to {fk['references_table']} by way of {fk['column']}")
description += "; ".be a part of(relationships) + "n"
# Add widespread use instances
use_cases = self._get_use_cases(table_name)
if use_cases:
description += f"Widespread queries: {use_cases}"
return description
def _get_use_cases(self, table_name: str) -> str:
"""Get widespread use instances for every desk."""
use_cases = {
'merchandise': 'product searches, catalog listings, value queries, stock checks',
'clients': 'buyer lookup, registration evaluation, geographic distribution',
'orders': 'gross sales evaluation, income monitoring, order historical past, standing monitoring',
'order_items': 'product gross sales efficiency, income by product, order composition',
'funds': 'cost processing, income reconciliation, cost technique evaluation',
'manufacturers': 'model efficiency, gross sales by model, model comparability',
'classes': 'class evaluation, product group, catalog construction'
}
return use_cases.get(table_name, 'common knowledge queries and evaluation')
def _load_table_names(self):
"""Load desk names from the gathering."""
if not self.assortment:
return
strive:
# Get all objects from assortment
outcomes = self.assortment.get()
self.table_names = [metadata['table_name'] for metadata in outcomes['metadatas']]
besides Exception as e:
print(f"⚠️ Couldn't load desk names from Chroma: {e}")
self.table_names = []
def get_relevant_schema(self, user_query: str, max_tables: int = 5) -> str:
"""Get related schema utilizing Chroma vector similarity search."""
if not self.assortment:
print("⚠️ Chroma not initialized, falling again to full schema")
return get_structured_schema(self.db_path)
strive:
# Seek for related tables
outcomes = self.assortment.question(
query_texts=[user_query],
n_results=max_tables
)
# Extract related desk names
relevant_tables = []
if outcomes['metadatas'] and len(outcomes['metadatas']) > 0:
for metadata in outcomes['metadatas'][0]:
relevant_tables.append(metadata['table_name'])
# Fallback if no related tables discovered
if not relevant_tables:
print("⚠️ No related tables discovered, utilizing defaults")
relevant_tables = self._get_default_tables(user_query)[:max_tables]
# Construct schema for chosen tables
return self._build_schema(relevant_tables)
besides Exception as e:
print(f"⚠️ Chroma search failed: {e}, falling again to full schema")
return get_structured_schema(self.db_path)
def _get_default_tables(self, user_query: str) -> Listing[str]:
"""Get default tables primarily based on question patterns."""
query_lower = user_query.decrease()
if any(phrase in query_lower for phrase in ['revenue', 'sales', 'total', 'amount', 'brand']):
return ['orders', 'order_items', 'product_variants', 'products', 'brands']
elif any(phrase in query_lower for phrase in ['product', 'item', 'catalog']):
return ['products', 'product_variants', 'categories', 'brands']
elif any(phrase in query_lower for phrase in ['customer', 'user', 'buyer']):
return ['customers', 'orders', 'addresses']
else:
return ['products', 'customers', 'orders', 'order_items']
def _build_schema(self, table_names: Listing[str]) -> str:
"""Construct schema string for specified tables."""
if not table_names:
return get_structured_schema(self.db_path)
conn = sqlite3.join(self.db_path)
cursor = conn.cursor()
schema_lines = ["Available tables and columns:"]
strive:
for table_name in table_names:
cursor.execute(f"PRAGMA table_info({table_name});")
columns = cursor.fetchall()
if columns:
col_names = [col[1] for col in columns]
schema_lines.append(f"- {table_name}: {', '.be a part of(col_names)}")
lastly:
conn.shut()
return 'n'.be a part of(schema_lines)
def get_approach_info(self) -> Dict[str, Any]:
return {
"identify": "Chroma Vector RAG",
"description": "Makes use of Chroma DB for persistent vector storage with semantic search",
"professionals": ["Persistent storage", "Fast queries", "Scalable", "Easy management"],
"cons": ["Requires disk space", "Initial setup time", "Additional dependency"],
"best_for": "Manufacturing environments, persistent workflows, crew collaboration"
}
Evaluating the completely different RAG Methods
This RAGManager class is the management heart for switching between completely different RAG methods. Primarily based on the person question, it picks the proper strategy, fetches probably the most related a part of the schema, and tracks efficiency like response time, token financial savings, and desk depend. It additionally has a examine perform to benchmark all RAGs side-by-side, and shops historic metrics so you possibly can analyze how each is doing over time. Tremendous helpful for testing what works greatest and conserving issues optimized.
All of the completely different RAG technique courses are initialized and saved in self.approaches. Every RAG strategy is a category that inherits from BaseRAG, so all of them have a constant interface (get_relevant_schema() and get_approach_info()). This implies you possibly can simply plug in a brand new technique (say Pinecone or Weaviate) so long as it extends BaseRAG.
The tactic get_relevant_schema() returns the schema related to that question primarily based on the chosen technique. If an invalid technique is handed or there’s a failure for some motive, it neatly falls again to the 'Key phrase RAG' technique.
The tactic compare_approaches() runs the identical question via all of the RAG methods. It measures:
- Size of ensuing schema
- % Token discount vs full schema
- Response time
- Variety of tables returned
That is actually helpful to benchmark methods side-by-side and choose the one greatest suited on your use case.
class RAGManager:
"""Supervisor for a number of RAG approaches."""
def __init__(self, db_path: str = DB_PATH):
self.db_path = db_path
self.approaches = {
'no_rag': NoRAG(db_path),
'key phrase': KeywordRAG(db_path),
'faiss': FAISSVectorRAG(db_path),
'chroma': ChromaVectorRAG(db_path)
}
self.performance_metrics = {}
def get_available_approaches(self) -> Dict[str, Dict[str, Any]]:
"""Get details about all accessible RAG approaches."""
return {
approach_id: strategy.get_approach_info()
for approach_id, strategy in self.approaches.objects()
}
def get_relevant_schema(self, user_query: str, strategy: str = 'key phrase', max_tables: int = 5) -> str:
"""Get related schema utilizing specified strategy."""
if strategy not in self.approaches:
print(f"⚠️ Unknown strategy '{strategy}', falling again to key phrase")
strategy = 'key phrase'
start_time = time.time()
strive:
schema = self.approaches[approach].get_relevant_schema(user_query, max_tables)
# Report efficiency metrics
end_time = time.time()
self._record_performance(strategy, user_query, schema, end_time - start_time)
return schema
besides Exception as e:
print(f"⚠️ Error with {strategy} strategy: {e}")
# Fallback to key phrase strategy
if strategy != 'key phrase':
return self.get_relevant_schema(user_query, 'key phrase', max_tables)
else:
return get_structured_schema(self.db_path)
def compare_approaches(self, user_query: str, max_tables: int = 5) -> Dict[str, Any]:
"""Examine all approaches for a given question."""
outcomes = {}
full_schema = get_structured_schema(self.db_path)
full_schema_length = len(full_schema)
for approach_id, strategy in self.approaches.objects():
start_time = time.time()
strive:
schema = strategy.get_relevant_schema(user_query, max_tables)
end_time = time.time()
outcomes[approach_id] = {
'schema': schema,
'schema_length': len(schema),
'token_reduction': ((full_schema_length - len(schema)) / full_schema_length) * 100,
'response_time': end_time - start_time,
'table_count': len([line for line in schema.split('n') if line.startswith('- ')]),
'success': True
}
besides Exception as e:
outcomes[approach_id] = {
'schema': '',
'schema_length': 0,
'token_reduction': 0,
'response_time': 0,
'table_count': 0,
'success': False,
'error': str(e)
}
return outcomes
def _record_performance(self, strategy: str, question: str, schema: str, response_time: float):
"""Report efficiency metrics for evaluation."""
if strategy not in self.performance_metrics:
self.performance_metrics[approach] = []
full_schema_length = len(get_structured_schema(self.db_path))
schema_length = len(schema)
metrics = {
'question': question,
'schema_length': schema_length,
'token_reduction': ((full_schema_length - schema_length) / full_schema_length) * 100,
'response_time': response_time,
'table_count': len([line for line in schema.split('n') if line.startswith('- ')]),
'timestamp': time.time()
}
self.performance_metrics[approach].append(metrics)
def get_performance_summary(self) -> Dict[str, Any]:
"""Get efficiency abstract for all approaches."""
abstract = {}
for strategy, metrics_list in self.performance_metrics.objects():
if not metrics_list:
proceed
avg_token_reduction = sum(m['token_reduction'] for m in metrics_list) / len(metrics_list)
avg_response_time = sum(m['response_time'] for m in metrics_list) / len(metrics_list)
avg_table_count = sum(m['table_count'] for m in metrics_list) / len(metrics_list)
abstract[approach] = {
'queries_processed': len(metrics_list),
'avg_token_reduction': spherical(avg_token_reduction, 1),
'avg_response_time': spherical(avg_response_time, 3),
'avg_table_count': spherical(avg_table_count, 1)
}
return abstract
# Comfort capabilities for backward compatibility
def get_rag_enhanced_schema(user_query: str, db_path: str = DB_PATH, strategy: str = 'key phrase') -> str:
"""Get RAG-enhanced schema utilizing specified strategy."""
supervisor = RAGManager(db_path)
return supervisor.get_relevant_schema(user_query, strategy)
# International cached occasion
_rag_manager_instance = None
def get_cached_rag_manager(db_path: str = DB_PATH) -> RAGManager:
"""Get cached RAG supervisor occasion."""
international _rag_manager_instance
if _rag_manager_instance is None:
_rag_manager_instance = RAGManager(db_path)
return _rag_manager_instanceThe Streamlit app is totally built-in with this supervisor, so customers can select the technique they need and see real-time outcomes. You possibly can try the entire code on GitHub right here. Right here’s a working demo of the brand new App in motion:
Ultimate Ideas
This isn’t the top; there’s nonetheless lots to enhance. I have to stress take a look at towards quite a lot of assaults and reinforce guardrails to scale back hallucinations and guarantee knowledge security. Will probably be good to construct a role-based entry system for knowledge governance. Possibly changing Streamlit with a frontend framework like React may make the app extra scalable for real-world deployments. All this, for subsequent time.
Earlier than you go…
Comply with me so that you don’t miss any new posts I write in future; you will see extra of my articles on my profile web page. You may also join with me on LinkedIn or X!








{kind=link}