As diffusion fashions dominating visible content material technology, efforts have been made to adapt these fashions for multi-view picture technology to create 3D content material. Historically, these strategies implicitly study 3D consistency by producing solely RGB frames, which might result in artifacts and inefficiencies in coaching. In distinction, we suggest producing Normalized Coordinate House (NCS) frames alongside RGB frames. NCS frames seize every pixel’s world coordinate, offering robust pixel correspondence and express supervision for 3D consistency. Moreover, by collectively estimating RGB and NCS frames throughout coaching, our strategy permits us to deduce their conditional distributions throughout inference by an inpainting technique utilized throughout denoising. For instance, given floor reality RGB frames, we are able to inpaint the NCS frames and estimate digicam poses, facilitating digicam estimation from unposed pictures. We practice our mannequin over a various set of datasets. Via intensive experiments, we exhibit its capability to combine a number of 3D-related duties right into a unified framework, setting a brand new benchmark for foundational 3D mannequin.
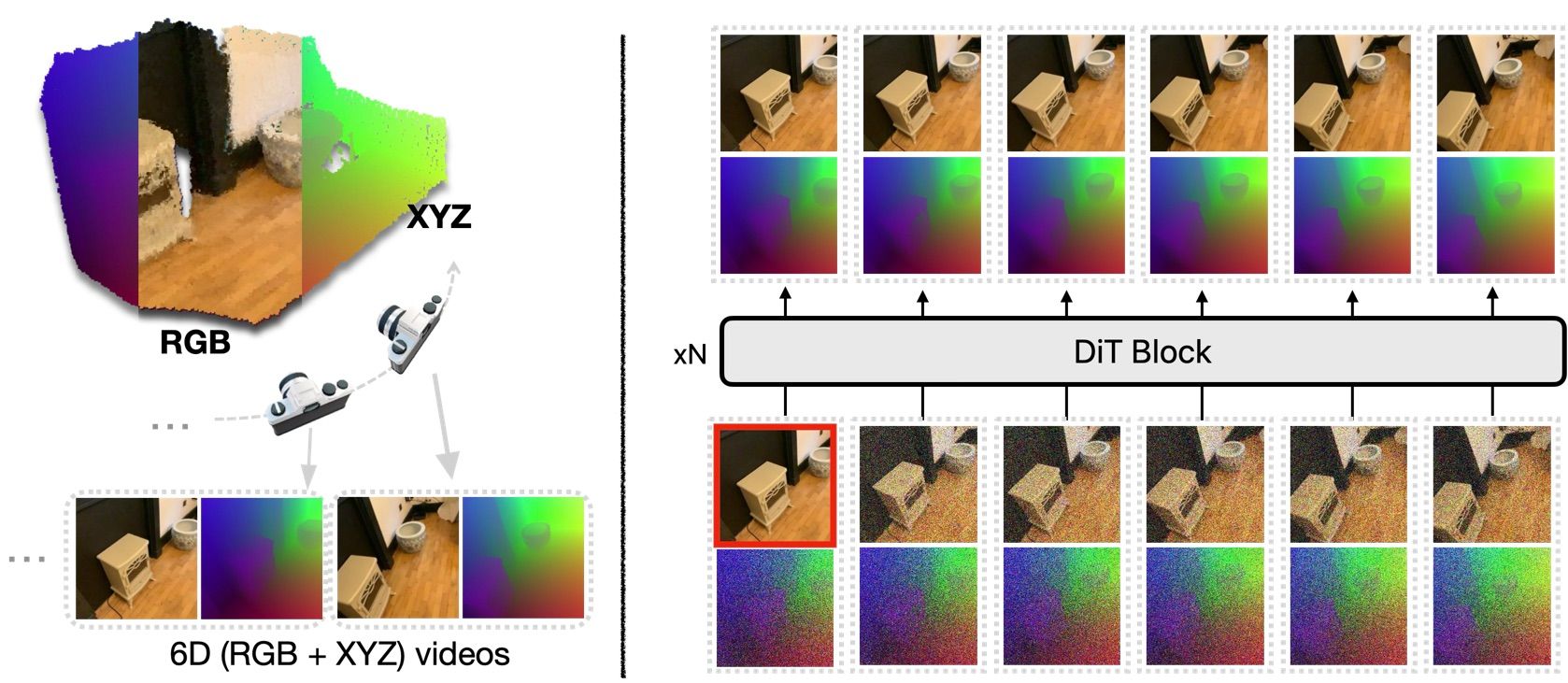
Determine 1: Pipeline of the proposed World-consistent Video Diffusion Mannequin.
- † The Chinese language College of Hong Kong
- ‡ Work performed whereas at Apple









{kind=link}