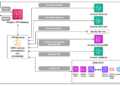
Encoder vs. Decoder
The unique Transformer had two halves: an encoder and a decoder, designed for sequence-to-sequence duties like translation. Fashionable LLMs usually use just one half, tailored for his or her particular objective.
Encoder-Solely Fashions
Encoder-only fashions course of your entire enter sequence without delay, with each token capable of attend to each different token, together with tokens that come after it (that is known as bidirectional consideration). They’re well-suited to duties that require understanding an entire enter, like classification, sentence similarity, or extracting solutions from textual content.
Instance: BERT. BERT is skilled utilizing masked language modeling — some tokens within the enter are hidden, and the mannequin should predict them utilizing context from each instructions. It’s broadly used for duties like search relevance, textual content classification, and named entity recognition, but it surely isn’t designed to generate free-flowing textual content.
Decoder-Solely Fashions
Decoder-only fashions use causal (masked) self-attention, the place every token can solely attend to itself and tokens earlier than it, by no means tokens after it. This makes them naturally suited to textual content technology, since producing textual content word-by-word requires solely understanding what got here earlier than.
Instance: GPT. The GPT household (and the overwhelming majority of recent chat-oriented LLMs, together with LLaMA, Mistral, Gemma, and Qwen) are decoder-only. This structure has grow to be the dominant alternative for general-purpose language fashions as a result of next-token prediction is a versatile coaching goal that scales properly and naturally helps open-ended technology.
Encoder-Decoder Fashions
These retain each halves: an encoder processes the enter, and a decoder generates output whereas attending each to beforehand generated tokens and to the encoder’s output (by way of cross-attention).
Instance: T5. T5 frames each job — translation, summarization, query answering — as a text-to-text downside, utilizing the encoder to course of the enter and the decoder to generate the output. This structure stays in style for duties with a transparent, distinct enter and output, comparable to machine translation.
The place Every Is Used
Structure Consideration Sort Finest Suited For Examples Encoder-only Bidirectional Classification, understanding duties BERT, RoBERTa Decoder-only Causal (masked) Open-ended textual content technology, chat GPT, LLaMA, Mistral, Gemma Encoder-Decoder Bidirectional + Cross-attention Translation, summarization T5, BART








{kind=link}