
Richard Sutton’s “Bitter Lesson” is normally learn as a warning towards constructing an excessive amount of human data into AI techniques. Over the long term, the strategies that win should not those that encode our intelligent instinct most straight, however the ones that scale: search, studying, and different normal strategies that may take in extra compute and knowledge.
Fashionable basis mannequin pre-training seems, at first look, like a triumph of that lesson. We take a normal structure, expose it to large knowledge, and prepare it with a easy self-supervised goal. Language fashions predict the subsequent token. Imaginative and prescient fashions reconstruct masked patches, align views, or match instructor representations. The recipe is easy and scalable.
However there’s a catch.
Pre-training might observe the Bitter Lesson in the way it trains the fashions, however not the way it chooses what the mannequin must be educated on. The target continues to be chosen exterior the coaching loop. We conduct a big pre-training run, consider downstream efficiency, modify the recipe, and run once more. The learner optimizes one self-supervised studying goal however the downstream suggestions truly arrives solely after the entire coaching course of. It is a very coarse management loop.
This paper asks whether or not that loop could be made extra direct and tighter. Our query is: given an unlabeled knowledge stream, and a small set of verifiable downstream examples, can we use these examples throughout continued pre-training? The proposed reply is value-based pre-training with downstream suggestions (V-pretraining). The important thing concept is to separate two roles which might be normally collapsed. There’s nonetheless a learner, the muse mannequin being pretrained. However there’s additionally a light-weight activity designer. The learner is up to date solely by a self-supervised loss on unlabeled knowledge. The designer, nonetheless, learns easy methods to assemble the self-supervised activity: which goal distribution to make use of in language modeling, or which views and masks to make use of in self-supervised imaginative and prescient coaching.
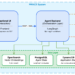
Determine 1 makes this distinction clear. Normal continued pretraining fixes a development rule earlier than coaching begins: for textual content, the next-token goal is a one-hot token; for imaginative and prescient, the crop, masks, or augmentation pipeline is mounted. V-pretraining replaces that mounted rule with a learnable designer, whereas protecting the learner’s replace self-supervised.
This distinction issues. V-pretraining is just not supervised fine-tuning, desire optimization, or reinforcement studying from suggestions. In these strategies, downstream labels, preferences, or rewards straight replace the learner. In V-pretraining, downstream examples are used solely to coach the duty designer. The learner by no means receives a downstream supervised gradient. The suggestions path is oblique.
One-step estimation
The technical query is how the designer is aware of which self-supervised activity is helpful. Ideally, we might select activity constructions that result in the very best downstream mannequin after a full continued-pretraining trajectory. However differentiating via a complete pretraining run is just not sensible. V-pretraining makes use of a neighborhood surrogate as a substitute.
Suppose a candidate self-supervised activity produces a pretraining gradient, (g_{rm pre}). A small suggestions batch produces a downstream gradient, (g_{rm down}). If we took a small learner step utilizing (g_{rm pre}), the downstream loss would change roughly as:
$$L_{rm down}(theta-eta g_{rm pre})approx L_{rm down}(theta) – eta g_{rm down}^{prime} g_{rm pre}$$
So the inside product (g_{rm down}^{prime} g_{rm pre}) estimates whether or not this unlabeled self-supervised replace is prone to scale back downstream loss. V-pretraining trains the designer to assemble duties whose learner gradients align with the downstream gradient. After that, the constructed targets or views are indifferent, and the learner takes an strange self-supervised replace.
Instantiations and primary outcomes
The concrete instantiations are easy and revealing. In language, we instantiate the duty design with adaptive top-Ok tender goal development. Normal next-token prediction makes use of a one-hot goal: the true subsequent token will get likelihood one. V-pretraining retains the identical textual content stream and context, however permits the designer to position a bounded quantity of likelihood mass over a small candidate set that all the time contains the true subsequent token plus high-probability options from the present learner. The learner nonetheless trains by cross-entropy on continued-pretraining textual content; the suggestions examples solely form the goal distribution via the designer.
In the primary language experiments, the learner is continued-pretrained on NuminaMath-CoT, whereas 1,024 GSM8K coaching examples are used solely as suggestions for the duty designer. Underneath matched wall-clock coaching budgets, V-pretraining improves GSM8K Cross@1 throughout examined Qwen fashions. The most important reported single-run achieve is for Qwen2.5-0.5B, enhancing from 22.20 to 29.60. In replicated Qwen1.5 runs, V-pretraining improves 0.5B, 4B, and 7B fashions, with the 4B mannequin transferring from 56.48±1.56 to 58.98±1.03.

In imaginative and prescient, the identical precept is utilized to self-supervised view development. The learner is a DINO-style visible spine educated on unlabeled ImageNet photographs. The designer modifies instance-wise views or masks in order that the ensuing self-supervised gradient higher aligns with downstream dense-prediction suggestions from ADE20K segmentation and NYUv2 depth estimation. The spine itself continues to be up to date solely by the self-supervised DINO loss.
The primary imaginative and prescient outcomes present the identical sample: goal downstream capabilities enhance with out apparent collapse of normal representations. For DINOv3-ViT-L, ADE20K mIoU improves from 51.33 to 52.47, NYUv2 RMSE improves from 0.5752 to 0.5522, and ImageNet-1K linear accuracy improves from 84.07 to 84.59. The paper additionally studies switch checks on picture retrieval, the place dense-task suggestions improves most Oxford/Paris retrieval protocols, although not uniformly.
A pure concern is that that is only a shortcut. Possibly the continued-pretraining knowledge comprises benchmark duplicates. Possibly tender labels assist no matter suggestions. Possibly the designer is secretly smuggling supervision into the learner.
The paper contains a number of controls towards these explanations. After decontaminating NuminaMath-CoT by eradicating near-duplicates of GSM8K and MATH, V-pretraining nonetheless stays above the baseline, though with a smaller margin. Random suggestions and uniform top-Ok smoothing carry out worse than the baseline within the Qwen1.5-4B ablation, whereas self-distillation improves however doesn’t match V-pretraining. These controls counsel that the achieve is not only label smoothing, self-distillation, contamination, or additional stochasticity; the downstream-aligned worth sign is doing work.
Does this lengthen the Bitter Lesson?
This brings us again to the Bitter Lesson. A shallow studying of the lesson may say: don’t inject downstream data into pre-training; simply scale next-token prediction. However that isn’t fairly the purpose. The lesson is just not that suggestions is dangerous. It’s that hand-designed construction tends to lose to normal strategies that may be taught from scalable alerts.
Present pre-training is simply partly “bitter.” The learner is educated by a scalable self-supervised goal, however the activity recipe continues to be normally mounted by hand. We select the information combination, masking rule, augmentation pipeline, goal format, and curriculum exterior the coaching loop. Downstream suggestions then arrives solely after a run is evaluated.
V-pretraining makes one a part of that recipe learnable. The learner nonetheless updates solely on unlabeled self-supervised knowledge, however a activity designer makes use of downstream suggestions to resolve which self-supervised prediction issues are prone to be helpful. Within the paper’s phrases, suggestions modifications the duty development slightly than straight supervising the learner.
That’s the extra bitter model of pre-training: not simply scaling a hard and fast proxy activity, however studying which proxy duties produce beneficial updates. Pre-training mustn’t solely be taught from knowledge. It ought to be taught what to foretell.
For extra particulars: Worth-Primarily based Pre-Coaching with Downstream Suggestions







{kind=link}