
AI is evolving past easy textual content interactions towards wealthy multimodal capabilities, equivalent to on-device picture and audio technology, enabling builders to create extremely customized client experiences. Whereas the CPU has at all times been the ever-present choice for inference, working giant complicated fashions on the edge has traditionally required selecting between high-latency CPU execution and fragmented, specialised accelerators.
Arm Scalable Matrix Extension 2 (SME2) eliminates this tradeoff by integrating a devoted matrix-compute unit straight into the CPU cluster. This structure allows the CPU to operate as a high-performance AI accelerator, delivering as much as 5x sooner inference for the matrix-heavy workloads on the coronary heart of generative AI.
Working on-device AI on Arm {hardware} is dramatically streamlined with Google AI Edge, an built-in stack designed to simplify your improvement journey. LiteRT robotically leverages Arm SME2 at runtime by means of XNNPACK and Arm KleidiAI integration. It identifies and selects math-intensive kernels like iGeMM and GeMM, delivering specialised {hardware} acceleration. To additional ease deployment, AI Edge Quantizer handles complicated mannequin compression, and Mannequin Explorer gives a visible map to rapidly determine and resolve efficiency hotspots.
The ability of this integration is confirmed by means of deploying Stability AI’s stable-audio-open-small mannequin fully on Arm CPUs delivering main efficiency uplift. On this weblog publish, we’ll stroll you thru remodeling the unique floating-point PyTorch stable-audio-open-small mannequin right into a extremely optimized, mixed-precision (FP16/Int8) implementation prepared for high-performance acceleration on Arm CPU.
Steady Audio Open Small working on LiteRT and Arm CPU with SME2
The problem: Balancing mannequin high quality and cell actuality
To generate high-quality audio, equivalent to 11-second stereo clips from a single immediate, straight on a variety of cell units, sensible concerns often require a manageable mannequin footprint, sometimes round 1 billion parameters. Even inside this Small Language Mannequin (SLM) vary, builders face Difficult Deployment Hurdles:
- Complexity Hole: Discovering the optimum quantization configuration amongst many prospects could be difficult. Moreover, naively quantizing the whole mannequin’s weights yields a extreme loss in audio high quality.
- Machine Protection: Unlocking a path for environment friendly CPU-based audio technology is greater than a technical milestone. It is a chance to scale revolutionary apps throughout the billions of CPU-powered units that symbolize the worldwide smartphone market.
Google AI Edge: A seamless path from PyTorch to silicon
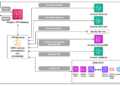
Through the use of a diffusion-based mannequin because the optimization goal, we reveal an entire end-to-end path with the Google AI Edge software program stack. As proven beneath, this synergy gives a streamlined Convert → Optimize → Deploy pipeline.
Given the KleidiAI optimizations are embedded straight into XNNPACK, builders acquire specialised AI acceleration robotically. There isn’t any want to jot down low-level meeting or customized {hardware} code; the stack handles the “translation” from high-level mannequin to silicon-optimized execution.
Convert: Convert from PyTorch to .tflite with LiteRT Torch
Begin by changing the PyTorch model of the Steady-audio-open-small mannequin into the AI Edge ecosystem. LiteRT-Torch permits for a direct conversion path for PyTorch fashions, minimizing friction of shifting from a analysis setting to a manufacturing cell setting.
import litert_torch
from litert_torch.quantize import quant_config
from litert_torch.generative.quantize import quant_recipe, quant_recipe_utils
# Specify the quantization format
quant_config_int8 = quant_config.QuantConfig(
generative_recipe=quant_recipe.GenerativeQuantRecipe(
default=quant_recipe_utils.create_layer_quant_dynamic(),
)
)
# Provoke the conversion
edge_model = ai_edge_torch.convert(
mannequin, example_inputs, quant_config=quant_config_int8
)Python
Discover the code snippet as an instance how LiteRT-Torch works in observe right here
Optimize: Optimize with Mannequin Explorer and AI Edge Quantizer
Beforehand, figuring out which layers of a mannequin have been appropriate for quantization was a handbook, error-prone technique of inspecting particular person layers.
With Google’s Mannequin Explorer, builders can now visualize the whole mannequin graph. The brand new node information overlay plugin permits us to see precisely which operators are most compute-intensive or as proven beneath that are “quantization-safe”. This visible verification ensures we solely goal layers the place shifting to INT8 will not degrade audio output high quality.
For instance, to enhance the inference effectivity of the diffusion step, we utilized dynamic INT8 quantization to the DiT (Diffusion Transformers) submodule:
Median distinction ratio error reported for every DiT transformer block.
As proven within the screenshot above, all layers within the DiT submodule are inexperienced, indicating low error values inside the DiT transformer (FP32 vs. FP32+INT8). Due to this fact, we anticipate the dynamically quantized INT8 DiT submodule to realize high quality similar to FP32.
Totally related layer with INT8 dynamic quantization. The error charge, reported underneath “NODE DATA PROVIDERS,” is roughly 1%.
As soon as the suitability of INT8 quantization was confirmed, we utilized the AI Edge Quantizer to optimize the mannequin from FP32 to INT8.
This resolution resulted in 3x efficiency enchancment within the DiT submodule, together with a 4x discount of its reminiscence utilization.
fp32_model_path = "./dit_model_fp32.tflite"
dynamic_quant_model_path = "./dit_model_int8+fp32.tflite"
the_recipe = [
dict({
'regex': '.*',
'operation': '*',
'algorithm_key': 'min_max_uniform_quantize',
'op_config': {
'weight_tensor_config': {
'num_bits': 8,
'symmetric': True,
'granularity': 'CHANNELWISE',
'dtype': 'INT',
'block_size': 0,
},
'compute_precision': 'INTEGER',
'explicit_dequantize': False,
'skip_checks': False,
'min_weight_elements': 0
},
})
]
# Outline the quantizer, with fp32 tflite mannequin, and the recipe.
qt = quantizer.Quantizer(fp32_model_path, the_recipe)
quant_result = qt.quantize().export_model(dynamic_quant_model_path, overwrite=True)Python
Deploy: Excessive-performance inference with LiteRT through XNNPack & KleidiAI
The ultimate step is the runtime.
Whenever you run this quantized mannequin in LiteRT on an Android cell system, it defaults to the XNNPACK delegate for CPU inference. As a result of XNNPACK integrates KleidiAI straight inside the newest LiteRT API, builders get these optimizations robotically. These micro-kernels be sure that the core INT8 and FP16 matrix multiplications of the audio mannequin run with most effectivity on the CPU.
Under is a consultant snippet of how LiteRT inference is applied in C++ utilizing the CompiledModel API. Directions on this information are supplied for working the audiogen app with LiteRT both on an Android™ system or macOS®.
#embody "litert/cc/litert_compiled_model.h"
#embody "litert/cc/litert_environment.h"
#embody "litert/cc/litert_tensor_buffer.h"
// 1. Initialize the LiteRT Surroundings
auto env = litert::Surroundings::Create({}).worth();
// 2. Create the CompiledModel from the .tflite file
// {Hardware} acceleration (e.g., SME2 through KleidiAI) is dealt with robotically
auto compiled_model = litert::CompiledModel::Create(
env, "autoencoder_model.tflite", litert::HwAccelerators::kCpu).worth();
// 3. Put together enter and output buffers
auto autoencoder_inputs = compiled_model.CreateInputBuffers().worth();
auto autoencoder_outputs = compiled_model.CreateOutputBuffers().worth();
// 4. Write enter information (e.g., random noise or conditioned embeddings)
auto auto_in_lock_and_ptr = scoped_lock(autoencoder_inputs[0],
litert::TensorBuffer::LockMode::kWrite);
// Fill the enter
// 5. Execute inference
compiled_model.Run(autoencoder_inputs, autoencoder_outputs);
// 6. Entry and skim the generated audio waveform from the output buffer
auto auto_out_lock_and_ptr = scoped_lock(autoencoder_outputs[0], litert::TensorBuffer::LockMode::kRead);
// Learn the output C++
Outcomes: Sooner, smaller, and high-quality audio technology with a decrease footprint
We now take our quantized fp16/int8 mannequin from the prior part and benchmark each CPU single threaded and multi-threaded (MT) efficiency with the unique FP32 Steady Audio Open Small mannequin towards our KleidiAI-optimized FP16 + INT8 mannequin on an SME2-based Android system and on an Apple MacBook with M4.
- Velocity: We noticed over 2x discount in audio technology time, from 10 seconds to only 4.3 seconds on an Apple MacBook M4 and down from 14 seconds to six.6 seconds on an Arm SME2-based Android system with 1 thread.
- Reminiscence: The DiT submodel measurement decreased by roughly 4x, considerably decreasing RAM utilization throughout inference.
- High quality: Crucially, the generated audio maintained perceptual parity with the FP32 model.
As proven within the bar chart above, SME2 delivers greater than a 2x efficiency enchancment over the NEON instruction set, specialised for sign processing duties. Even with a single core, it might generate 11 seconds of audio in underneath 8 seconds, which is suitable from a user-experience perspective.
Able to be taught extra?
These optimizations can be found for builders at the moment. Begin experimenting instantly utilizing Google AI Edge instruments and KleidiAI-accelerated LiteRT.
Begin experimenting at the moment
Discover Arm’s pattern repository to entry the entire end-to-end journey for Steady Audio Open:
- Convert: Use LiteRT-torch to convey your PyTorch fashions into the ecosystem.
- Optimize: Use Google AI Edge instruments, together with Mannequin Explorer and the AI Edge Quantizer, to visualise and compress your fashions for the sting.
- Deploy: Run the pattern code for Steady Audio Open Small on Arm-powered telephones and laptops to see the Arm SME2 acceleration in motion.
Developer assets
- Obtain LiteRT: Entry the most recent OSS or Maven variations to make sure you are utilizing the most recent XNNPACK engine, now supercharged with Arm KleidiAI micro-kernels.
- Google AI Edge Documentation: Go to the LiteRT Documentation for complete improvement guides on mannequin conversion and {hardware} delegation.
- Arm Developer Portal: Discover extra about Arm SME2 and KleidiAI to know find out how to unlock most throughput on the most recent Armv9-A CPUs.
Acknowledgements
Arm: Adnan Alsinan, Anitha Raj, Aude Vuilliomenet, Bala Gattu, Declan Cox, and Gian Marco Iodice
Stability AI credit score: This publish makes use of the Steady Audio Open Small mannequin by Stability AI, launched underneath the Stability AI Group License. Audio samples have been generated utilizing the mannequin working on take a look at units through LiteRT & Arm Keidi AI.
Google: Advait Jain, Andrei Kulik, Changmin Solar, Cormac Brick, Dillon Sharlet, Eric Yang, Jinjiang Li, Jing Jin, Lu Wang, Maria Lyubimtsev, Meghna Johar, Pedro Gonnet, Ram Iyengar, Sachin Kotwani, Terry (Woncheol) Heo, Vitalii Dziuba








{kind=link}