Apple is advancing AI and ML with basic analysis, a lot of which is shared via publications and engagement at conferences so as to speed up progress on this necessary discipline and help the broader neighborhood. This week, the Fourteenth Worldwide Convention on Studying Representations (ICLR) will likely be held in Rio de Janeiro, Brazil, and Apple is proud to once more take part on this necessary occasion for the analysis neighborhood and to help it with sponsorship.
On the primary convention and related workshops, Apple researchers will current new analysis throughout quite a lot of subjects, together with work unlocking large-scale coaching for Recurrent Neural Networks, a method for bettering State Area Fashions, a brand new strategy to unifying picture understanding and technology, a technique for producing 3D scenes from a single picture, and a brand new strategy to protein folding.
Throughout exhibition hours, attendees will have the ability to expertise demonstrations of Apple’s ML analysis in our sales space #204, together with native LLM inference on Apple silicon with MLX and Sharp Monocular View Synthesis in Much less Than a Second. Apple can be sponsoring and taking part in a variety of affinity group-hosted occasions that help underrepresented teams within the ML neighborhood.
A complete overview of Apple’s participation in and contributions to ICLR 2026 will be discovered right here, and a choice of highlights follows under.
Recurrent Neural Networks (RNNs) are naturally suited to environment friendly inference, requiring far much less reminiscence and compute than attention-based architectures, however the sequential nature of their computation has traditionally made it impractical to scale up RNNs to billions of parameters. A brand new development from Apple researchers makes RNN coaching dramatically extra environment friendly — enabling large-scale coaching for the primary time and widening the set of structure selections obtainable to practitioners in designing LLMs, notably for resource-constrained deployment.
In ParaRNN: Unlocking Parallel Coaching of Nonlinear RNNs for Giant Language Fashions, a brand new paper accepted to ICLR 2026 as an Oral, Apple researchers share a brand new framework for parallelized RNN coaching that achieves a 665× speedup over the standard sequential strategy (see Determine 1). This effectivity acquire allows the coaching of the primary 7-billion-parameter classical RNNs that may obtain language modeling efficiency aggressive with transformers (see Determine 2).
To speed up analysis in environment friendly sequence modeling and allow researchers and practitioners to discover new nonlinear RNN fashions at scale, the ParaRNN codebase has been launched as an open-source framework for computerized training-parallelization of nonlinear RNNs.
At ICLR, the paper’s first creator will even ship an Expo Speak about this analysis.
Speedup from Parallel RNN Coaching
Efficiency of Giant-Scale Basic RNNs
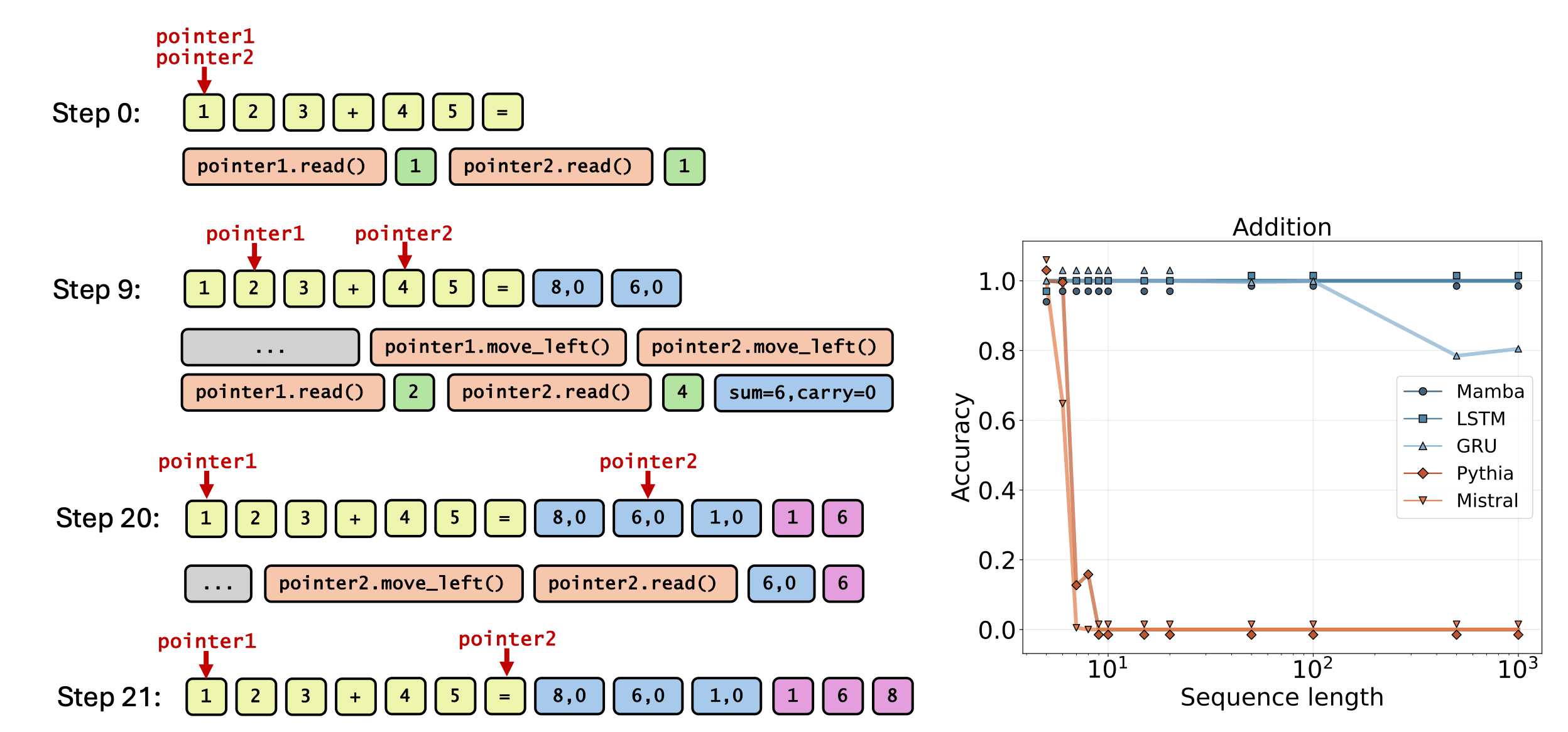
State Area Fashions (SSMs) like Mamba have turn into the main different to Transformers for sequence modeling duties. Their major benefit is effectivity in long-context and long-form technology, enabled by fixed-size reminiscence and linear scaling of computational complexity. To Infinity and Past: Device-Use Unlocks Size Generalization in State Area Fashions, a brand new Apple paper accepted as an Oral at ICLR, explores the capabilities and limitations of SSMs for long-form technology duties. The paper exhibits that the effectivity of SSMs comes at a value of inherent efficiency degradation. Actually, SSMs fail to unravel long-form technology duties when the complexity of the duty will increase past the capability of the mannequin, even when the mannequin is allowed to generate chain-of-thought (CoT) of any size. This limitation arises from the bounded reminiscence of the mannequin, which limits the expressive energy when producing lengthy sequences.
The paper exhibits that this limitation will be mitigated by permitting SSMs interactive entry to exterior instruments. Given the suitable selection of instrument entry and problem-dependent coaching information, SSMs can be taught to unravel any tractable drawback and generalize to arbitrary drawback size and complexity (see Determine 3). The work demonstrates that tool-augmented SSMs obtain sturdy size generalization on quite a lot of arithmetic, reasoning, and coding duties. These findings spotlight SSMs as a possible environment friendly different to Transformers in interactive tool-based and agentic settings.
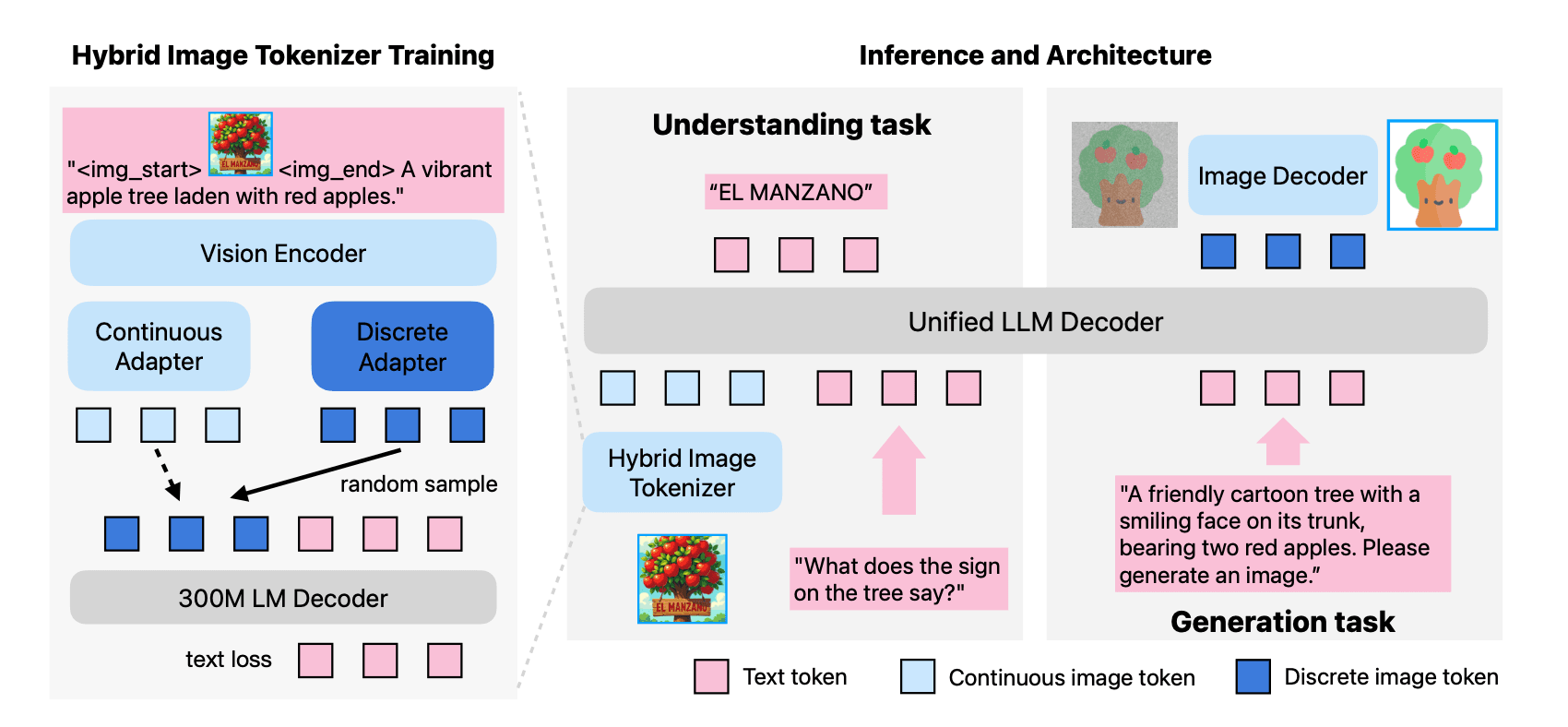
Unified multimodal LLMs that may each perceive and generate photographs are interesting not just for architectural simplicity and effectivity, but in addition as a result of shared representations may end up in deeper understanding and higher vision-language alignment, and may allow distinctive capabilities like picture enhancing via directions.
Nonetheless, present open-source fashions usually endure from a efficiency trade-off between picture understanding and technology capabilities. At ICLR, Apple researchers will share MANZANO: A Easy and Scalable Unified Multimodal Mannequin with a Hybrid Imaginative and prescient Tokenizer. As described within the paper, Manzano is a unified framework designed to cut back this efficiency trade-off with a easy architectural concept (see Determine 4) and a coaching recipe that scales effectively throughout mannequin sizes.
Manzano makes use of a single shared imaginative and prescient encoder to feed two light-weight adapters that produce steady embeddings for image-to-text understanding and discrete tokens for text-to-image technology inside a shared semantic house. A unified autoregressive LLM predicts high-level semantics within the type of textual content and picture tokens, and an auxiliary diffusion decoder then interprets the picture tokens into pixels. This structure, along with a unified coaching recipe over understanding and technology information, allows scalable joint studying of each capabilities. Manzano achieves state-of-the-art outcomes amongst unified fashions, and is aggressive with specialist fashions, notably on text-rich analysis.
At ICLR, Apple researchers will even share Sharp Monocular View Synthesis in Much less Than a Second, which presents a technique for producing a 3D Gaussian illustration from {a photograph}, utilizing a single ahead cross via a neural community in lower than a second on a regular GPU. The ensuing illustration can then be rendered in actual time from close by views, as a high-resolution photorealistic 3D scene (see Determine 5).
Referred to as SHARP (Single-image Excessive-Accuracy Actual-time Parallax), this method delivers a illustration that’s metric, with absolute scale, supporting metric digicam actions. Experimental outcomes show that SHARP delivers sturdy zero-shot generalization throughout datasets. It additionally units a brand new cutting-edge on a number of datasets, decreasing LPIPS by 25-34% and DISTS by 21-43% versus the most effective prior mannequin, whereas reducing the synthesis time by three orders of magnitude.
To allow the neighborhood to additional discover and construct on this strategy, code is accessible right here.
ICLR attendees will have the ability to expertise this work firsthand in a demo on the Apple sales space #204 throughout exhibition hours.

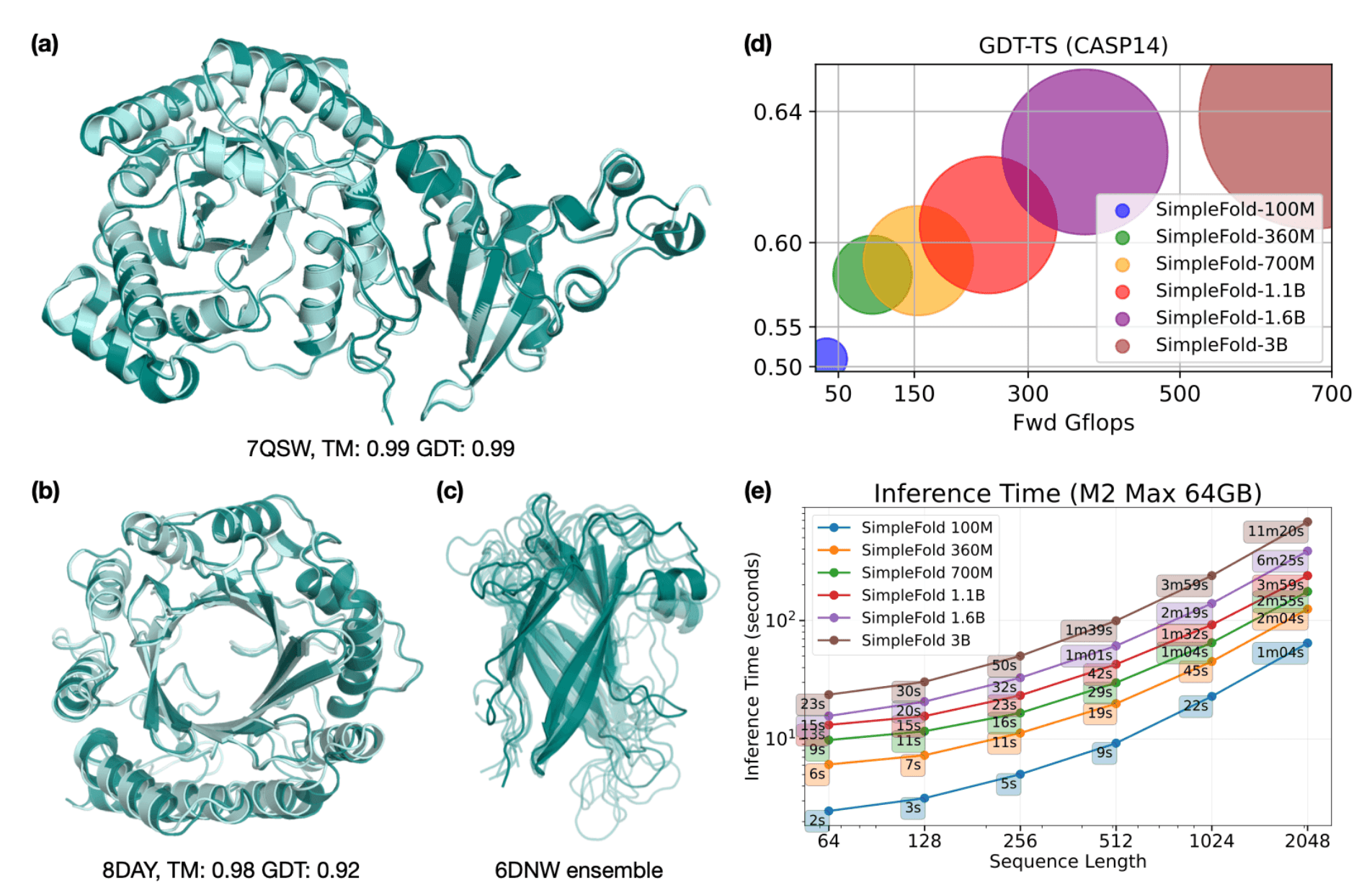
Protein folding is a foundational but notoriously difficult drawback in computational biology. At its core, this drawback includes predicting the exact three-dimensional coordinates for every atom inside a protein construction, primarily based solely on its amino acid sequence (i.e., a string of characters with 20 attainable values for every character). Predicting the 3D construction of proteins is critically necessary as a result of a protein’s perform is inherently linked to its spatial configuration. Breakthroughs on this space allow researchers to quickly design and perceive proteins, doubtlessly revolutionizing drug discovery, biotechnology, and past.
At ICLR, Apple researchers will share SimpleFold: Folding Proteins is Less complicated than You Suppose, which particulars a brand new strategy that makes use of a general-purpose structure primarily based solely on normal transformer blocks (just like text-to-image or text-to-3D fashions). This strategy permits SimpleFold to dispense with the complicated architectural designs of prior approaches, whereas sustaining efficiency (see Determine 6). To allow the analysis neighborhood to construct on this methodology, the paper is accompanied by code and mannequin checkpoints that may be effectively run domestically on Mac with Apple silicon utilizing MLX.
Throughout exhibition hours, ICLR attendees will have the ability to work together with dwell demos of Apple ML analysis in sales space #204 together with:
- SHARP – This demo exhibits SHARP working on a set of pre-recorded photographs or photographs captured straight by the consumer in the course of the demo. Guests will expertise the quick course of from deciding on a picture, processing it with SHARP, and viewing the generated 3D Gaussian level cloud on iPad Professional with the M5 chip.
- Native LLM inference on Apple silicon with MLX – This demo will showcase on-device LLM inference on a MacBook Professional with M5 Max utilizing MLX, Apple’s open-source array framework purpose-built for Apple silicon, working a quantized frontier coding mannequin solely domestically inside Xcode’s native growth surroundings. The total stack — MLX, mlx-lm, and mannequin weights — is open supply, inviting the analysis neighborhood to construct on and prolong these strategies independently.
We’re proud to once more sponsor affinity teams internet hosting occasions onsite at ICLR, together with Ladies in Machine Studying (WiML) (social on April 24), and Queer in AI (social on April 25). Along with supporting these teams with sponsorship, Apple staff will even be taking part in these and different affinity occasions.
ICLR brings collectively professionals devoted to the development of deep studying, and Apple is proud to once more share revolutionary new analysis on the occasion and join with the neighborhood attending it. This submit highlights only a choice of the works Apple ML researchers will current at ICLR 2026, and a complete overview and schedule of our participation will be discovered right here.









{kind=link}