Enterprise RAG 2.0 (Retrieval-Augmented Technology) will not be a expertise improve – it’s an architectural dedication. Organizations that deal with retrieval-augmented technology as a chatbot characteristic uncover, often too late, that the failure level isn’t the LLM. It’s the info pipeline behind it. This information explains the place deployments break and what a production-grade Python-powered technique truly requires.
A mid-sized monetary companies agency in Chicago spent eight months constructing a retrieval augmented technology Python pipeline. The demo handed each inner overview. The mannequin answered questions precisely. Compliance signed off. Manufacturing hit a wall on day three – not as a result of the LLM was fallacious, however as a result of the retrieval layer couldn’t deal with the doc quantity at question pace with out degrading. Three engineers, eight months, and a tough lesson concerning the distinction between a working prototype and a production-ready RAG pipeline.
That story isn’t uncommon. Based on analysis by Databricks, vector databases supporting RAG purposes grew 377% year-over-year, but solely 17% of organizations attribute significant EBIT impression to their GenAI deployments. The hole between constructing and scaling is the place most enterprise RAG packages stall – and it’s virtually by no means attributable to the mannequin itself.
Enterprise RAG 2.0 is the maturation of the unique retrieve-then-generate idea into one thing able to working at manufacturing scale throughout heterogeneous enterprise knowledge. Python’s ecosystem is what makes that maturation sensible. However getting there requires understanding the strategic structure earlier than the technical execution – and that sequence is the place most organizations get it backwards.
What You Ought to Know First:
- Enterprises are selecting RAG for 30–60% of their AI use instances the place accuracy and knowledge privateness matter most (Vectara, 2025).
- The RAG market was valued at $1.2 billion in 2024 and is projected to succeed in $11 billion by 2030 at a 49.1% CAGR (Grand View Analysis).
- Most RAG failures hint again to retrieval high quality, chunking technique, and re-ranking – to not the LLM alternative.
- Agentic RAG, the place AI methods retrieve and act slightly than simply reply, is the subsequent manufacturing frontier for enterprise AI utility improvement.
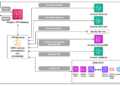
- A Python-powered RAG 2.0 stack requires a minimum of 5 specialised layers: ingestion, embedding, vector storage, orchestration, and deployment – every with distinct failure modes.
- 70% of organizations utilizing LLMs are actually counting on vector databases and RAG to attach proprietary knowledge to fashions (Databricks State of AI Report).
The Perception Most Groups Miss Till It’s Costly
Most enterprise groups consider RAG by asking: which LLM produces one of the best solutions? That’s the fallacious beginning query. The sincere reply is that reply high quality is sort of completely a downstream operate of retrieval high quality – and retrieval high quality is set by selections made earlier than a single question is processed. Chunking technique. Embedding mannequin choice. Vector database configuration. Metadata structure. Get these fallacious, and no LLM rescues the output.
The counterintuitive half: including a extra highly effective LLM to a weak retrieval layer doesn’t enhance the system. It amplifies the noise. The mannequin turns into extra assured in fallacious solutions as a result of it’s working with poor context – a sample known as “assured hallucination” that’s tougher to detect than a clearly fallacious response. For this reason organizations uncover their RAG failures in manufacturing slightly than in testing.
RAG 1.0 vs. RAG 2.0: What Modified on the Structure Degree
The unique RAG sample – embed a doc, retailer the vectors, retrieve top-Ok, generate – works nicely for single-document prototypes. Enterprise RAG 2.0 and Agentic AI improvement introduce developments that make the structure production-ready: multi-source ingestion, hybrid search combining semantic and key phrase retrieval, re-ranking with cross-encoder fashions, and parent-document retrieval that avoids the context-truncation downside.
The sensible implication is {that a} Python RAG pipeline for enterprise use must be designed for operational complexity from the beginning, not bolted collectively incrementally. Every layer within the stack handles a definite failure mode. Skip the re-ranking step and the LLM receives a set of retrieved chunks which might be semantically much like the question however contextually misaligned. Skip hybrid search and the system performs nicely on idea queries however fails on exact-match necessities like product codes or contract clauses.
The place Enterprise RAG Applications Reliably Break Down
4 failure patterns account for almost all of stalled enterprise RAG deployments. They’re not technical edge instances – they’re architectural selections made early within the challenge that floor as manufacturing issues six months later.
Failure Level 1: Chunking Technique Chosen for Comfort, Not Semantics
Mounted-size chunking is the default in most tutorials. It’s additionally the quickest path to retrieval degradation at scale. When a 500-token chunk splits a contractual clause throughout two segments, the retrieval system can’t floor the entire obligation – it surfaces a fraction. In authorized, compliance, or monetary doc use instances, that fragment misleads the LLM. Superior RAG 2.0 implementations use semantic chunking, parent-document retrieval, and overlapping home windows to protect contextual integrity.
Failure Level 2: Vector-Solely Search in a Hybrid Information Surroundings
Semantic vector search finds conceptually associated content material. That’s exactly the fitting device for some queries and the fallacious device for others. A question for “income determine Q3 FY24” requires precise key phrase precision, not conceptual proximity. Hybrid search, combining BM25 key phrase matching with semantic vector retrieval through LangChain RAG manufacturing configurations, captures each sign varieties. Organizations that deploy vector-only search report increased false-positive retrieval charges on structured knowledge queries – and people false positives compound by way of the technology step.
Failure Level 3: No Re-ranking Layer Between Retrieval and Technology
Preliminary vector retrieval returns the top-Ok candidates by embedding similarity. That set is commonly adequate for demos. In manufacturing, it’s the second go – the cross-encoder re-ranking mannequin – that determines which candidates are really related to the particular question. With out re-ranking, the LLM receives a loud context window. With it, precision on advanced multi-clause queries improves considerably. Based on benchmarks from the LlamaIndex enterprise deployment group, including a re-ranking step reduces irrelevant context by 40–60% in document-heavy use instances.
Failure Level 4: Treating Agentic RAG as a Future Drawback
RAG 2.0 solutions questions. Agentic RAG acts on data. The distinction issues as a result of enterprise workflows hardly ever finish at “right here is the reply.” A procurement system that retrieves a provider contract clause must replace a discipline within the CRM, flag an exception within the compliance queue, and notify the class supervisor – all from a single question outcome. Organizations that design their RAG structure with out agentic extension factors face pricey refactoring when enterprise necessities catch as much as the expertise. The frameworks that make agentic extension sensible – CrewAI, LangGraph – are Python-native, which is why the language alternative issues past developer familiarity.

The Flexsin RAG 2.0 Strategic Structure Framework
The Flexsin RAG 2.0 Strategic Structure Framework organizes enterprise RAG deployment throughout 4 maturity levels: Prototype, Manufacturing, Scale, and Agentic. Most organizations enter on the Prototype stage and assume Manufacturing is identical vacation spot reached at increased quantity. It isn’t. Every stage requires distinct architectural selections.
Stage 1: Prototype – Validate the Retrieval Speculation
The Prototype stage assessments whether or not your knowledge is retrieval-ready earlier than any manufacturing dedication. The Python stack right here is deliberately light-weight: PyPDF2 or Docling for doc ingestion, SentenceTransformers for embeddings, ChromaDB for native vector storage, LangChain for orchestration. The aim is to not construct manufacturing infrastructure – it’s to check chunking methods and embedding mannequin high quality towards your particular doc corpus.
Stage 2: Manufacturing – Construct the Retrieval Layer That Scales
Manufacturing requires changing ChromaDB with a scalable vector database like Qdrant, implementing hybrid search through BM25 + semantic retrieval, and including a cross-encoder re-ranking step. FastAPI serves the backend; the retrieval layer connects to the LLM through the orchestration framework. That is the place 70% of enterprise groups underinvest – they transfer the Prototype stack to a cloud server and name it manufacturing, then encounter efficiency degradation at doc volumes above 50,000.
Stage 3: Scale – Govern the Information Pipeline
At scale, the bottleneck strikes from retrieval structure to knowledge governance. Which paperwork are listed? When is the vector database up to date when supply paperwork change? How does the system deal with conflicting data throughout doc variations? These questions haven’t any technical reply with out an organizational course of behind them. The retrieval augmented technology Python structure at this stage contains automated ingestion pipelines, metadata tagging, and doc freshness monitoring.
Stage 4: Agentic – Transfer from Solutions to Actions
Agentic RAG connects retrieval and technology to downstream actions: updating data, routing workflows, triggering alerts, calling exterior APIs. The Python frameworks that allow this – CrewAI for multi-agent orchestration, LangGraph for stateful agent workflows – require that the sooner levels are steady. Organizations that try Agentic RAG on an unstable Manufacturing stage amplify their present retrieval failures throughout automated workflows. The sequence will not be elective.
Flexsin in Observe
At Flexsin, our AI utility improvement Python follow has delivered enterprise RAG 2.0 implementations throughout monetary companies, healthcare, and document-intensive authorized workflows. One mid-market insurance coverage provider within the UK – working throughout 12 doc administration methods, 1.8 million coverage paperwork – retained us to construct a production-grade retrieval system connecting their legacy knowledge to a contemporary LLM interface. The engagement started with a retrieval speculation check slightly than a construct dash: we recognized that their fixed-size chunking technique was producing 34% irrelevant retrievals on claims queries. Changing it with semantic chunking and parent-document retrieval lowered that charge to eight% earlier than a line of manufacturing code was written.
Our generative AI consulting services strategy treats enterprise RAG as a knowledge structure downside first and an AI downside second. That sequence adjustments what will get constructed. Most organizations we have interaction have succesful improvement groups and strong LLM entry. The hole is sort of all the time in retrieval technique, embedding mannequin choice for domain-specific corpora, and the absence of a re-ranking layer. We shut these gaps by way of the Flexsin RAG 2.0 Strategic Structure Framework, then construct the agentic extension factors that enable the system to develop into multi-step workflow automation with out architectural rework.
What Mature RAG Appears Like: Named Outcomes
Manufacturing-grade enterprise RAG 2.0 deployments share three observable traits that distinguish them from scaled prototypes.
First, retrieval precision above 85% on domain-specific queries. This threshold, achievable with hybrid search and cross-encoder re-ranking, is the place LLM-generated solutions turn into operationally dependable slightly than review-required. Under it, human verification prices negate the effectivity positive factors.
Second, sub-two-second end-to-end question latency at enterprise doc quantity. Reaching this with a Python RAG pipeline requires deliberate vector database index configuration – particularly approximate nearest-neighbor (ANN) indexing for databases like Qdrant or FAISS at scale. The default configurations of most vector databases usually are not optimized for question efficiency above 100,000 paperwork.
Third, agentic extension with out architectural refactoring. Clever enterprise AI purposes which might be designed with LangGraph or CrewAI integration factors from the beginning can develop from question-answering to workflow automation with out rebuilding the retrieval layer. Organizations that construct this fashion spend their second 12 months extending functionality, not rewriting infrastructure.
Clear Commerce-offs
Enterprise RAG 2.0 will not be a common resolution, and any vendor who presents it as one is promoting the fallacious factor. RAG is the fitting structure when your use case calls for excessive accuracy on proprietary knowledge that adjustments steadily. It’s the fallacious structure when your knowledge is static and sufficiently small that fine-tuning produces extra constant outcomes, or when question patterns are extremely structured and a standard SQL question would outperform vector retrieval on precision.
The overall price of possession is increased than most organizations anticipate. Vector databases at enterprise scale require infrastructure, monitoring, and ongoing index administration. Embedding fashions want periodic re-evaluation as area language evolves. Re-ranking fashions add latency that should be offset towards precision positive factors. These aren’t arguments towards RAG 2.0 – they’re arguments for designing the enterprise case with full operational prices included, not simply mannequin inference prices.
Agentic RAG introduces error propagation danger that doesn’t exist in answer-only methods. When a retrieval error causes a fallacious reply, a human reviewer catches it. When a retrieval error triggers an automatic workflow motion, the downstream impression compounds earlier than anybody opinions it. Organizations shifting into Agentic RAG want human-in-the-loop controls on high-consequence actions till the retrieval precision metrics justify lowered oversight.
Individuals Additionally Ask:
What’s the distinction between RAG 1.0 and RAG 2.0 in enterprise purposes?RAG 1.0 retrieves paperwork from a single supply utilizing primary vector similarity. RAG 2.0 provides hybrid search, re-ranking, multi-source ingestion, and agentic extension factors for production-scale enterprise use.
Is Python the fitting language for constructing enterprise RAG 2.0 methods?Python’s ecosystem – LangChain, LlamaIndex, SentenceTransformers, Qdrant, FastAPI – covers each layer of a manufacturing RAG pipeline. No different language has equal library depth for this structure.
How does retrieval high quality have an effect on LLM output accuracy in RAG methods?LLM output accuracy is sort of completely downstream of retrieval high quality. A robust LLM on a weak retrieval layer produces assured however deceptive solutions, which is tougher to detect than apparent errors.
When ought to an enterprise contemplate Agentic RAG over normal enterprise RAG 2.0?When the use case requires downstream motion – updating data, routing approvals, calling APIs – based mostly on retrieved data. Commonplace RAG 2.0 solutions questions; Agentic RAG acts on them.
Work With Flexsin on Your Enterprise RAG 2.0 Technique
Flexsin’s AI utility improvement Python follow helps enterprises design, construct, and scale production-grade RAG 2.0 methods – from retrieval structure by way of to agentic workflow integration. We begin with a retrieval speculation check that identifies your particular failure factors earlier than any manufacturing funding is made.
Our generative AI consulting companies have delivered RAG implementations throughout monetary companies, insurance coverage, healthcare, and authorized doc administration. In case your workforce is hitting the wall between prototype and manufacturing, that’s exactly the place we work.
Contact Flexsin Applied sciences.
Widespread Questions Answered:
1. What does enterprise RAG 2.0 imply in follow?It means a retrieval-augmented technology system constructed for manufacturing scale: multi-source ingestion, hybrid search, re-ranking, and agentic extension. It’s not a single product however an architectural normal.
2. How does a Python RAG pipeline deal with doc ingestion at enterprise scale?Libraries like Docling deal with advanced PDF parsing together with tables. Automated ingestion pipelines handle doc freshness and metadata tagging throughout giant corpora.
3. What vector database ought to a enterprise use for enterprise RAG 2.0?ChromaDB fits prototyping; Qdrant handles enterprise scale with environment friendly ANN indexing. FAISS is efficient for native high-volume search with out a managed service.
4. What’s hybrid search and why does it matter for enterprise RAG 2.0 hallucination discount?Hybrid search combines semantic vector search with BM25 key phrase matching. It improves retrieval precision on exact-match queries the place semantic similarity alone underperforms.
5. How lengthy does it take to construct a production-ready RAG pipeline?A well-scoped manufacturing RAG 2.0 deployment usually requires 12–20 weeks. Prototype-to-production timelines prolong when retrieval structure selections are revisited mid-project.
6. What’s the function of LangChain in an enterprise RAG 2.0 system?LangChain supplies orchestration: it manages retrieval, immediate development, and LLM interplay inside a single framework. LlamaIndex provides comparable capabilities with stronger indexing abstractions.
7. How does re-ranking enhance RAG output high quality?A cross-encoder re-ranking mannequin evaluates retrieved candidates in context of the particular question. It reduces irrelevant context reaching the LLM by 40–60% on advanced doc queries.
8. What’s agentic RAG and the way does it differ from normal RAG 2.0?Commonplace RAG retrieves and generates solutions. Agentic RAG connects that output to downstream actions – updating methods, routing workflows, calling APIs – through frameworks like LangGraph or CrewAI
9. What’s the RAG vs fine-tuning resolution for enterprise AI?RAG fits use instances with steadily altering proprietary knowledge. Tremendous-tuning fits static area data the place behavioral consistency issues greater than knowledge freshness.
10. How does Flexsin strategy enterprise RAG 2.0 engagements?Flexsin begins with a retrieval speculation check earlier than any manufacturing construct. This identifies chunking, embedding, and re-ranking failures that may in any other case floor in manufacturing.








{kind=link}