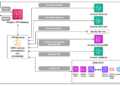
Regardless of their refined general-purpose capabilities, Massive Language Fashions (LLMs) typically fail to align with various particular person preferences as a result of customary post-training strategies, like Reinforcement Studying with Human Suggestions (RLHF), optimize for a single, international goal. Whereas Group Relative Coverage Optimization (GRPO) is a extensively adopted on-policy reinforcement studying framework, its group-based normalization implicitly assumes that each one samples are exchangeable, inheriting this limitation in customized settings. This assumption conflates distinct person reward distributions and systematically biases studying towards dominant preferences whereas suppressing minority alerts. To handle this, we introduce Personalised GRPO (P-GRPO), a novel alignment framework that decouples benefit estimation from speedy batch statistics. By normalizing benefits in opposition to preference-group-specific reward histories reasonably than the concurrent era group, P-GRPO preserves the contrastive sign obligatory for studying distinct preferences. We consider P-GRPO throughout various duties and discover that it constantly achieves sooner convergence and better rewards than customary GRPO, thereby enhancing its capacity to get well and align with heterogeneous desire alerts. Our outcomes show that accounting for reward heterogeneity on the optimization stage is important for constructing fashions that faithfully align with various human preferences with out sacrificing normal capabilities.








{kind=link}