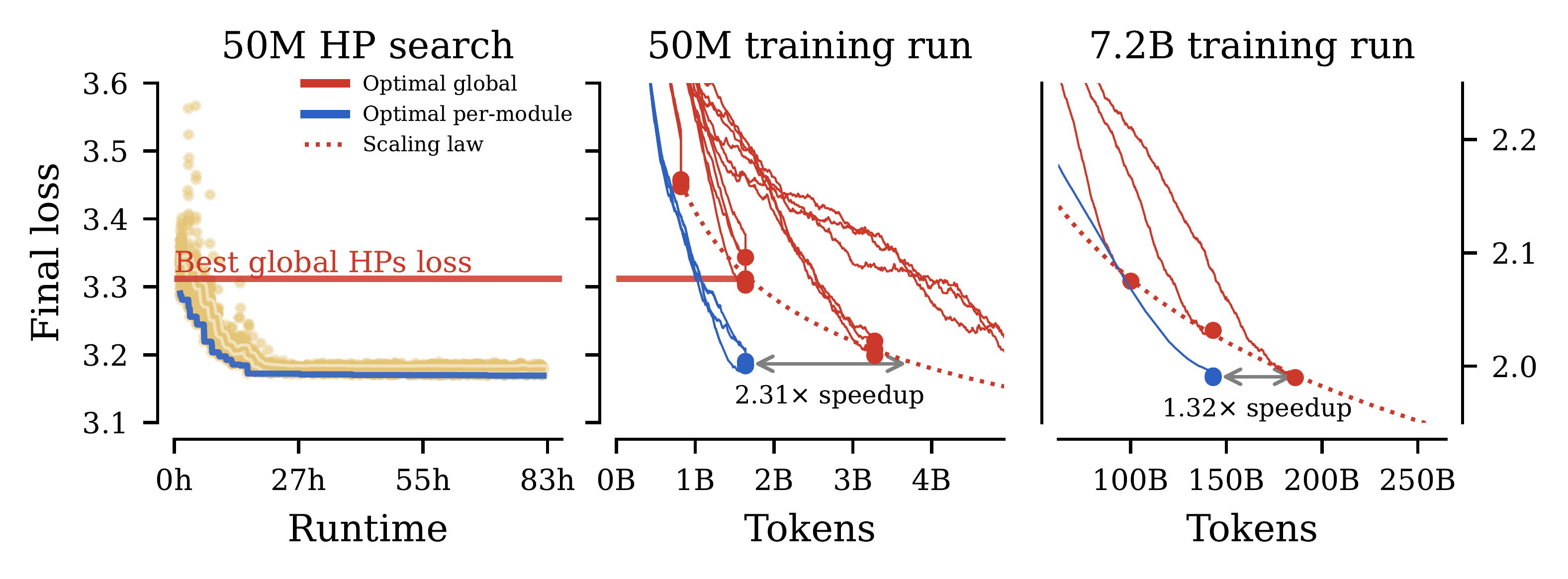
Hyperparameter tuning can dramatically impression coaching stability and closing efficiency of large-scale fashions. Current works on neural community parameterisations, comparable to μP, have enabled switch of optimum world hyperparameters throughout mannequin sizes. These works suggest an empirical observe of seek for optimum world base hyperparameters at a small mannequin dimension, and switch to a big dimension. We prolong these works in two key methods. To deal with scaling alongside most essential scaling axes, we suggest the Full(d) Parameterisation that unifies scaling in width and depth — utilizing an adaptation of CompleteP — in addition to in batch-size and coaching length. Secondly, with our parameterisation, we examine per-module hyperparameter optimisation and switch. We characterise the empirical challenges of navigating the high-dimensional hyperparameter panorama, and suggest sensible pointers for tackling this optimisation drawback. We reveal that, with the proper parameterisation, hyperparameter switch holds even within the per-module hyperparameter regime. Our research covers an intensive vary of optimisation hyperparameters of recent fashions: studying charges, AdamW parameters, weight decay, initialisation scales, and residual block multipliers. Our experiments reveal vital coaching pace enhancements in Giant Language Fashions with the transferred per-module hyperparameters.
- † College of Cambridge
- ** Work performed whereas at Apple








{kind=link}